
|
Site Sponsored By: SQLDSC - SQL Server Desired State Configuration
|
|
Notes from an Upgrade to SQL Server 2005By Bill Graziano on 26 February 2007 | Tags: Installation I recently worked with a client to upgrade their main database server from SQL Server 2000 to SQL Server 2005. Along the way I learned a few things and thought I'd share them. This article is a random collection of my "Thoughts from an Upgrade." This client does specialized credit card processing. The server processes authorizations and settlements. It processes a fairly limited group of statements all inside stored procedures. A "business transaction" was made up of roughly fourteen stored procedures depending on the transaction type. Processing times were typically between 100ms and 300ms on the old server. The database was roughly 20GB. Most of the transactions came from retailer authorizations or financial settlements coming in from a major credit card association. The client developed a testing harness that leverages a transaction repository to replay transactions. The harness can be throttled to simulation various per second transaction loads. The flexibility of the tool allowed for numerous transaction scenarios. This proved to be a fantastic little tool that let us find all kinds of strange little problems. The New ServerOur new server has two dual-core 64-bit CPUs with 16GB of RAM. In our testing we found that enabling hyper-threading increased our throughput even on a heavily loaded server. I think that was due to the fact that we had no reporting at all on this server. The new server was attached to a SAN that had 20 spindles in RAID10 for the data and 4 spindles in RAID10 for the logs. It was nice having a 64-bit server and not worrying about configuring AWE memory -- everything just worked. Rebuilding the IndexesOur conversion process was to back up the SQL Server 2000 database and restore it to SQL Server 2005. For testing we had a script that would restore the database to SQL Server 2005, set it to "SQL Server 2005" compatibility level and then we'd launch our tests. Our initial tests were slower than our old server. Our performance dropped from 100ms to over 400ms. After a little research that we determined that rebuilding the indexes fixed this problem. We also ran DBCC UPDATEUSAGE and sp_updatestats on the database. Our transactions were now running well under 100ms. We also did some testing on the fastest way to rebuild indexes. We're using the Enterprise Edition so we had the option of doing an online index rebuild so the system would be available sooner. SQL Server 2005 also ads an option to specify the MAXDOP for the index rebuild. A little testing on a table with a few hundred-thousand rows gave us these results: 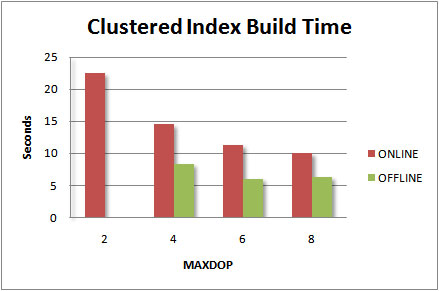
Offline index rebuilds were much faster than online index rebuilds. We also saw this when we ran this over the entire database. With two dual-core hyper-threaded processors SQL Server sees eight processors. Using all eight gave us the fastest build times. Using less than eight reduced the load on the system. I wish I'd also charted disk reads and writes while monitoring the index rebuilds. My suspicion is that we can use MAXDOP to "tune" the amount of resources that SQL Server uses to rebuild the indexes. I like the SAN!Our old server was very disk bound. During the checkpoint process we'd see large spikes in processing time when the disk drives couldn't keep up. With twenty spindles and 4 GB of RAM on the SAN it just swallowed the checkpoints without a problem. Our time to restore a database dropped from 25 minutes to 4 minutes which allowed us more test runs during the day. We did a lot of testing with SQLIO.EXE to try and find the baseline throughput. This should give us a better idea of the performance limits on the SAN. Fault ToleranceOne of the goals of this new server was to improve the fault tolerance. We started testing database mirroring prior to buying the new server. In our initial testing of synchronous mirroring we weren't happy with the response time. It seemed to be adding a few hundred milliseconds to our transaction times. As a result we ended up buying a cluster. Later we figured out those extra milliseconds were the result of not rebuilding the indexes. At that point we were far enough down the cluster path that we didn't want to go back. Clustering is also a more mature technology than mirroring. We were on a tight deadline and wanted to eliminate as many possibilities for surprises as possible. If you're considering some type of fault-tolerance I'd strong consider mirroring. It seems solid and I'm guessing performance will be just fine if you rebuild your indexes. We did learn one very interesting thing about clustering during this process. We have a testing environment that is identical to the production environment. The standard rollout process is to build the machine in the test environment and then move it into production. We discovered that once a cluster is built in one domain it can't be moved to another domain without reinstalling SQL Server. Apparently the installation process embeds domain specific security information at a very deep level. After we tried to trick SQL Server into actually moving domains we decided it was safest to just reinstall everything on the cluster. ReplicationWe decided to use replication to create two near real-time reporting servers. I haven't used replication in a long, long time and it has greatly improved since I worked with it last. We replicated every table in a 20GB database without any problem. We had a dedicated box for a distribution server and did continuous transactional replication. During our load testing we were able to test the reporting servers just handling the replication load. I was very impressed. Just processing replicated transactions put a very light load on the reporting servers. Since they were much less powerful than our main server and we were very happy to see such a light load. We also saw a very light load on our distribution server. We experience a three to five second latency for transactions to move from the transaction server to the report servers. This result was without any tuning of replication at all and was good enough for our reporting. We chose to initialize replication with a backup rather than generating a snapshot through SQL Server. We already had backups lying around and we didn't want the extra load on the server from generating snapshots. SSMS doesn't support initializing a snapshot from a backup. This meant we had to script out most of our replication tasks rather than using the GUI. That's a good practice anyway but it pushed us toward it much quicker. PerformanceOne of our goals was to find the top end performance of the new server. One of the interesting aspects of this application was the way transactions arrive at the server. In most of the systems I'd worked with previously users submit transactions and wait for the results. If the server slows down the user can't submit any more transactions until they get their results. In this case the transactions just keep coming. If the server ever gets behind it's difficult to catch up. The test harness was written to send transactions at a continuous rate regardless of how quickly SQL Server responds. We got up to 1200 stored procedures per second but found that our client applications were breaking at that point. The CPU was around 35%, page life expectancy was over 1000 and our disk I/O's weren't near the limit of the SAN at all so we still had plenty of headroom. SummaryOverall I was very happy with the upgrade. Part of initializing replication involved configuring it, backing up the database and then restoring the backup on the reporting servers. The main transaction server was ready to go pretty quickly. Even with fast disks and networks setting up replication took a little longer. All in all it made for a long night. The client did provide us with every type of caffeinated drink I'd ever seen and quite a few I'd never even heard of before. I also want to say Thanks to Geoff Hiten for help with SANs and Hilary Cotter for help with replication.
|
- Advertisement - |