|
datakeyword
Starting Member
10 Posts |
 Posted - 2014-01-27 : 04:52:40 Posted - 2014-01-27 : 04:52:40
|
The columnar storage is good, especially when there are lots of tabular fields (this is quite common). In querying, the data to traverse is far less than that on the row storage. Less data to traverse brings less I/O workloads and higher query speed. However, the Hadoop application consumes most time on the hard disk I/O without columnar storage.Both Hive and Impala support columnar storage, but columnar storage only available with the basic SQL interface. As for some more complex data computing, it seems quite difficult for the MapReduce framework to do columnar storage. The sample data is a big data file sales.txt on the HDFS. This file has twenty fields, 100 million data entries, and the file size is 14G. Let’s take the GROUP computing for example to demonstrate the whole procedure. Concretely speaking, it is to summarize the total sales for everyone by the sales person. The algorithm involves two fields, empID and amount.Firstly, compare it with the classic code for Grouping and Summarizing on Columnar Storage:Code for summary machine: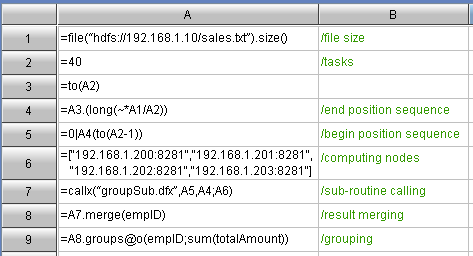 Code for node machine: Code for node machine: The above columnar storage algorithm follows such train of thought: Scheduling a large task into forty smaller tasks according to the file bytes; distribute them to the node machine for the initial summarization; and then further secondary summarize on the summary machine. This train of thoughts is similar to that for MapReduce. The difference is that this columnar storage thinking pattern is simple and intuitive because the task scale could be customized, and most people can understand it easily.As can be seen, the row storage is to store all fields in the file in the form of fields. Therefore, no matter there are two or twenty fields, we still have to traverse all data - the file of 14 G. However, the columnar storage is not like this. The data of each field are stored as a file. If only two fields are stored in the query, then you only need to retrieve the corresponding file of these two fields, i.e. 1.4 G. Please note that the 1.4 G is an average value. The total volume of the data of the two fields is slightly higher than 1.4 G.As mentioned above, to implement the columnar storage, we must decompose the file field by field first, by using f.cursor() to retrieve first and then f.export() to export. The detailed procedure about columnar storage will be explained at the end of this article.Code for Grouping and summarizing once Columnar Storage is adopted:Code for summary machine: The above columnar storage algorithm follows such train of thought: Scheduling a large task into forty smaller tasks according to the file bytes; distribute them to the node machine for the initial summarization; and then further secondary summarize on the summary machine. This train of thoughts is similar to that for MapReduce. The difference is that this columnar storage thinking pattern is simple and intuitive because the task scale could be customized, and most people can understand it easily.As can be seen, the row storage is to store all fields in the file in the form of fields. Therefore, no matter there are two or twenty fields, we still have to traverse all data - the file of 14 G. However, the columnar storage is not like this. The data of each field are stored as a file. If only two fields are stored in the query, then you only need to retrieve the corresponding file of these two fields, i.e. 1.4 G. Please note that the 1.4 G is an average value. The total volume of the data of the two fields is slightly higher than 1.4 G.As mentioned above, to implement the columnar storage, we must decompose the file field by field first, by using f.cursor() to retrieve first and then f.export() to export. The detailed procedure about columnar storage will be explained at the end of this article.Code for Grouping and summarizing once Columnar Storage is adopted:Code for summary machine: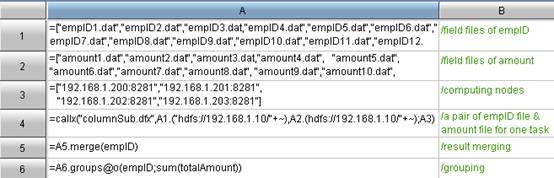 Code for node machine: Code for node machine: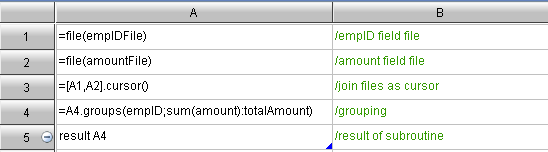 As can be seen, the greatest change is the code for node machine. The A3 cell uses the [file list]. Use the cursor() to merge a group of field files to generate a cursor of 2 dimension table. The remaining codes for grouping and summarizing are just the same as before.Another change is about the task-scheduling. In fact, great trouble can be caused in this stage. As we know, in the row storage, the task-scheduling can be performed based on the number of byes. For example, a 14 G file can be divided into 40 segments evenly, and each segment will be assigned to a node machine as a task. But this method does not work in the columnar storage because of the record misalignment, and the result can be always wrong. The right method is to divide evenly by the number of records (Any suggestions on dividing it evenly, please leave a comment. Thanks.). 100 million entries can be allocated to 40 segments, and each segment will hold 2’500’000 entries.For example, the empID column will be ultimately divided into 40 smaller files: empID1. dat”,”empID2. dat”……”empID40. dat”. Then, the algorithm codes are shown below: As can be seen, the greatest change is the code for node machine. The A3 cell uses the [file list]. Use the cursor() to merge a group of field files to generate a cursor of 2 dimension table. The remaining codes for grouping and summarizing are just the same as before.Another change is about the task-scheduling. In fact, great trouble can be caused in this stage. As we know, in the row storage, the task-scheduling can be performed based on the number of byes. For example, a 14 G file can be divided into 40 segments evenly, and each segment will be assigned to a node machine as a task. But this method does not work in the columnar storage because of the record misalignment, and the result can be always wrong. The right method is to divide evenly by the number of records (Any suggestions on dividing it evenly, please leave a comment. Thanks.). 100 million entries can be allocated to 40 segments, and each segment will hold 2’500’000 entries.For example, the empID column will be ultimately divided into 40 smaller files: empID1. dat”,”empID2. dat”……”empID40. dat”. Then, the algorithm codes are shown below: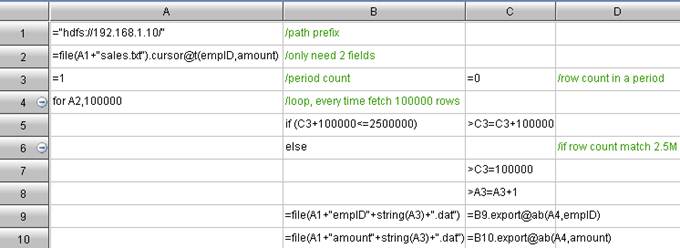 In order to prevent the memory overflow, the above algorithm will retrieve 100’000 entries from cursor, and append to the file. By doing this, a new file will be created with every 2’500’000 entries of data. In which, A3 is the file count, C3 is used to monitor if the data entries in the current files reaches 2.5 M.The data-scheduling is surprisingly troublesome, but the columnar computing after splitting is quite simple.Web: [url]http://www.raqsoft.com/[/url]Jim KingBI technology consultant for Raqsoft10 + years of experience on BI/OLAP application, statistical computing and analyticsEmail: Contact@raqsoft.comWebsite: www.raqsoft.comBlog: datakeyword.blogspot.com/ In order to prevent the memory overflow, the above algorithm will retrieve 100’000 entries from cursor, and append to the file. By doing this, a new file will be created with every 2’500’000 entries of data. In which, A3 is the file count, C3 is used to monitor if the data entries in the current files reaches 2.5 M.The data-scheduling is surprisingly troublesome, but the columnar computing after splitting is quite simple.Web: [url]http://www.raqsoft.com/[/url]Jim KingBI technology consultant for Raqsoft10 + years of experience on BI/OLAP application, statistical computing and analyticsEmail: Contact@raqsoft.comWebsite: www.raqsoft.comBlog: datakeyword.blogspot.com/ |
|
